转载地址: https://caoxudong818.iteye.com/blog/1388880
原文在这里。
简介
文章的第2章首先介绍了并发垃圾回收器的实现与实验的平台;第3章对原始并发算法进行了介绍;第4章介绍了作者采用的算法;在第5章中对该算法进行了实验,用来对实现结果进行评估;在第6章中对相关工作进行了介绍,即 增量式垃圾回收;第7章中给出了结论和将来的工作。
平台
作者使用的平台是Sun公司自己研发的一款虚拟机,Research VM,其前身是Exact VM。该VM是准确式虚拟机,通过一套定义好的GC接口,将内存系统与虚拟机的其他部分分离开,这样其他类型的GC就可以使用这套接口,达到模块化的目的。此外,还有一个名为分代式框架(generational framework)的中间层,用于实现分代式GC。 原始算法 原始的并发垃圾回收算法由Boehm等人提出,是一种并发的“三色”垃圾回收器。它使用一个写屏障(write barrier)来更新堆中对象的属性域,将置为灰色。这种算法的主要特点是,用并发换取更好的吞吐量,即允许对根集合(包括全局对象、栈上对象和寄存器中的对象)进行更新操作时,不需要使用写屏障。该算法会在适当时候挂起mutator(对象更新方法),但通常是一个很短的时间。该算法包括4个阶段:
- 初始标记暂停(Initial marking pause):挂起所有mutator方法,标记所有可从根集合直达的对象。
- 并发标记阶段(Concurrent marking phase):恢复mutator的操作,同时初始化并发标记阶段,标记可达对象的传递闭包。但这种方法无法正在标记结束后所有的可到对象都在这个闭包中,因为在标记的过程中,mutator可能会更新对象的属性域。为了解决这个问题,算法还要跟踪所有对堆中对象的属性域的更新。这是垃圾回收器和mutator之间唯一的交互。
- 最终标记阶段(Final marking phase):再次挂起所有mutator。从根集合开始标记,并且将已标记的对象中更新过的属性域作为额外的根集合。由于这些属性域只包含在并发标记阶段没有观测到的引用,所以这就保证了最终的传递闭包中会包含所有的可达对象。但是,这个闭包中也会包含在并发标记阶段变为不可达的对象,这些对象将在下一次垃圾回收中处理。
- 并发清理阶段(Concurrent sweeping phase):再次恢复mutator,并发清理堆,回收未标记对象。但要注意不能回收那些新分配的对象。至少在这个阶段中,是通过将新分配对象标记为live实现的。
该算法假设堆中对象更新操作并不会很多,否则在最终标记阶段将不得不重新扫描大量的属性域,这将导致一个长时间的程序暂停。据Boehm等人报告指出,该算法在实际应用中效果不错。
算法示例
示意图如下:
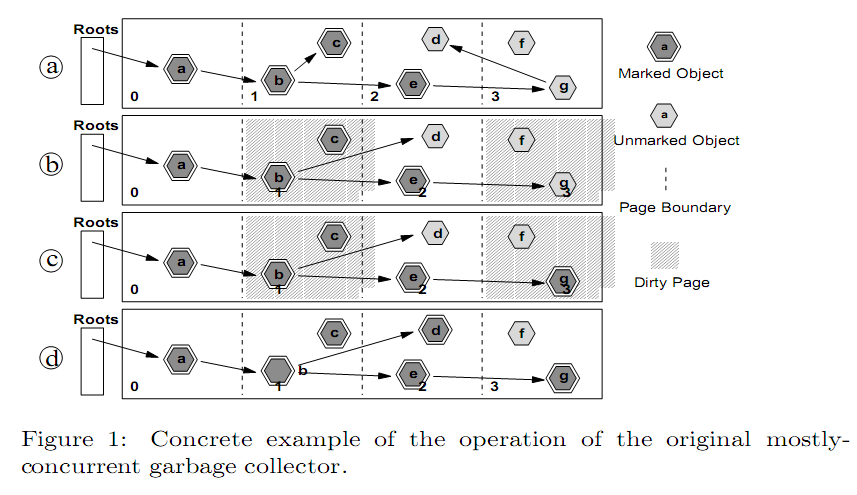
在这个示例中,堆中包含有7个对象,堆被分为4个页。在初始标记阶段中(该阶段不在此图中),4个页都被标记为clean,对象a标记为live。 图1a展示了并发标记阶段中堆的情况。对象b、c和e已经被标记。这是mutator执行了两个更新,取消g对d的引用,将b对c的引用改为对d的引用。也就是图1b中的情况,这两个更新是堆中的2个页成为“脏页”。图1c展示了并发标记阶段结束时的情况。很明显,标记并不完整,即对象d还没有被标记。这将在最终标记阶段完成,会脏页中所有已标记对象重新进行扫描。图1d展示了最终标记阶段后的情况,这时标记完成,开始并发清理,回收对象f。 由于对象f在垃圾回收之前就已经是不可达的,所以肯定会被回收掉。但是,对象c是在垃圾回收过程中变为不可达的,因此无法保证可以在当此垃圾回收中被回收掉,但会在下一次垃圾回收中回收掉。
分代式系统的并发垃圾回收
分配器
在Research VM的默认配置中,年轻代使用拷贝垃圾回收,老年代使用标记-整理垃圾回收。由于在整理堆的过程中以移动对象,需要更对被移动的对象的引用,所以并发垃圾回收器不会对内存进行整理,而是使用空闲列表进行内存分配操作。
空闲列表按对象大小进行划分,一种是将一些小对象划分到一个空闲列表中(列表上限是100个4字节的字的大小),另一种是按照一些大对象组成的组的大小划分空闲列表(这些组的选取是按照类似Fibonacci数列选择的)。大部分mutator分布内存都是在年轻代中,可以实现高效率的线性分配。 这里可以讨论的是,一个智能的分配器可以实现较快的分配速度和较少的内存碎片。事实上,Johnstone和Wilson认为,分离的空闲列表分配策略可能会产生最糟糕的内存碎片情况。但是,这是在假设“在线”回收的情况下,代表情况是使用C语言的malloc和free接口。在“离线”状态下,有垃圾回收器在清理阶段合并连续的空闲空间来降低内存碎片是比较容易实现,且比较有效率的。
使用卡表(Card Table)
分代垃圾回收需要跟踪从老年代到年轻代的引用。在年轻代中,有些对象如果没有这些跨代引用,就会变成不可达对象。因而需要一个更加简便的方法进行垃圾回收,而不是遍历整个老年代来查找跨代引用,否则对年轻代的垃圾回收就会变得像对整个堆进行垃圾回收一样。 Research VM使用卡表来记录这种跨代引用。卡表是一个数组,其中的每个元素对应于堆中的一块区域,称为“一个卡片”。在使用卡表的情况下,mutator对堆中对象进行更新时,会将对应与该对象所在的卡片标记为dirty。为了有更好的效率,这里并不会检查该对象是否真的引用了年轻代对象,脏的卡片只表明有可能会有老年代到年轻代的引用。 在并发垃圾回收器中,这种方法正好可以得到利用。 在虚拟内存页这个粒度上,Boehm等人使用虚拟内存保护技术来跟踪指针更新:一个“脏”页中包含了一个或多个被修改过的引用。相对于这种方法,使用基于卡表的写屏障有以下几种优势:
- 更低的开销:在大多数操作系统中,调用对内存保护陷阱调用自定义的处理程序具有较大的性能损耗。Hosking和Moss找到了一种基于卡标记屏障的方法,只有5个指令,比基于页保护的屏障更有效率;而Research VM中只用了2个到3个指令。
- 更好的粒度:卡表的力度可以根据准确性和空间消耗来选择。在虚拟内存保护模式下,卡片的大小就是内存页的大小。这个数值用来优化一些属性,例如磁盘传输效率,但垃圾回收却完全不关注这个。一般来说,这些关注点造成页的大小比跟踪引用更新所需要的大小要大,一般来说至少是4KB。相比之下,Research VM中卡片的大小是512B。
- 更准确的类型信息:在Research Vm中,当某个卡片中的引用类型被更新后,才会将该卡片标记为“脏”的。基于虚拟内存的系统无法区分出对标量域和引用域的更新,因此产生了额外的脏卡片。Hosking、Moss和Stefantic对软件实现和基于页保护的屏障实现进行了详细讨论,基本结论是软件实现更有效率。 并发垃圾回收算法需要在当前标记阶段开始后,跟踪所有对引用的更新。年轻代垃圾回收需要知道所有从老年代到年轻的引用。在基本的分代式系统中,年轻代垃圾回收需要遍历老年代中所有脏的卡片,搜索指向年轻代的指针。如果卡片中没有这样的指针,那么在下次垃圾回收中就不需要扫描这个卡片,这个卡片就被标记为clean。在年轻代垃圾回收将某个卡片标记为clean之前,卡片中被修改了的信息会被并发垃圾回收器记录下来。 这个功能是通过mod union table实现的。如图2所示。
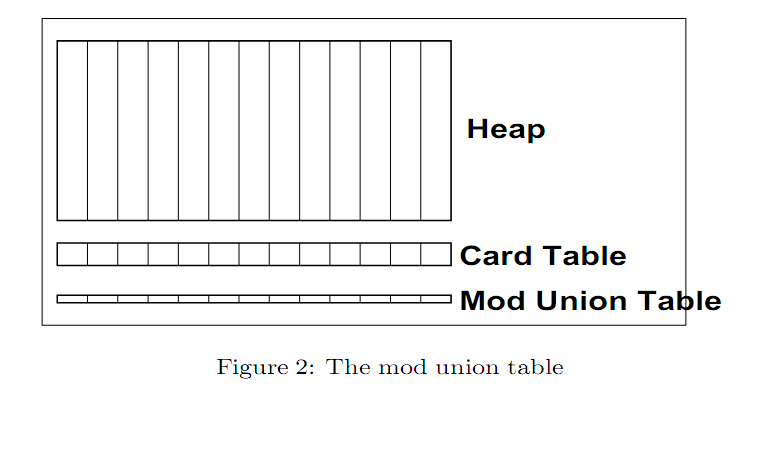
之所以称之为mod union table,是因为它表示发生在当前标记过程中,两次年轻代垃圾回收之间修改了的卡片集合。在Research VM中,卡片本身包含一个字节,这样就可以通过一个字节来实现一个快速的写屏障。另一方面,mod union table是一个位向量表,每个卡片一位。因此,额外的空间消耗很小。这里有一个不变的原则,每个卡片都包含了在当前并发标记阶段修改了的引用,或者在union set table中置位,或者将该表标记为dirty,或者两者都做。该原则由年轻代垃圾回收维护,它会在扫描脏卡片之前,将卡表中所有的脏卡片在union set table中置位。
标记对象
当前的并发垃圾回收器中包含了一个外部标记位数组。该位图中每一位都表示了堆中每个长度为4字节的字。使用外部标记位,而不是用对象头中内部标记位,可以防止mutator和垃圾回收器在使用对象时的相互干扰。 并发垃圾回收算法在进行根扫描时会挂起mutator,因此这个过程越快越好。但另一方面,还需要一个待标记对象集合,通常是栈或队列结构。为了降低STW(Stop the world)的时间,可以简单的将所有可达对象都放到这个外部数据结构中。但是,由于Java本身对多线程的支持,所以根集合中会包含寄存器、线程栈帧和各代中的对象都被认为是根集合的一部分。这样,根集合可能就会很大。 另一种降低空间消耗的策略是标记从根集合可立即到达的对象,并将其作为根。有很多对象对根来说都是可达的,每次都将这些放到待扫描对象集合中,在任何给定时间内,可以最小化空间消耗。这种方法适用于非并发垃圾回收,但不适用并发垃圾回收,因为在根扫描过程中,它要完成所有的标记。 这里,使用了一个折中的方法。根扫描仅仅标记那些从根可直达的对象,最小化STW时间,通过使用标记位来表示待扫描对象集合,也无需更多的空间消耗。然后,在并发标记阶段,对堆进行线性遍历。这个过程的消耗与堆的大小相关,与live对象的数量无关。 对每个找到的cur对象,将其放到待扫描对象集合中(是一个栈),然后执行一个循环,从栈中弹出对象,并扫描它的引用域,直到栈为空。对引用ref的扫描过程如下所示:
- 如果ref指向的对象在cur前面,则直接标记该对象,无需将其放到栈中,它会在后续的线性遍历中被访问到。
- 如果ref指向的对象在cur后面,则标记该对象并将其放入到栈中。
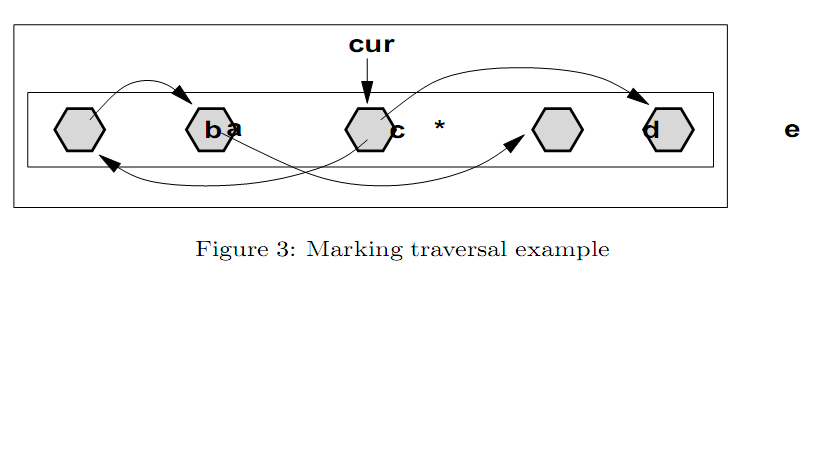
图3中对这个过程进行了说明。标记遍历发现了一个标记对象c,其地址是cur。扫描c,找到有2个对外引用,分别是a和e。对象e仅仅进行了标记,因为它的地址跟在c后面。对象a在cur前面,所以它会被标记并扫描。这就会扫描到对象b,它的地址也在c前面,所以也会被标记并扫描。但是对象b的引用d只会被标记,因为d的地址在c后面,它会在遍历过程中被扫描。 这种方法可以降低对待扫描对象集合的要求,因为只会有一个根可直达的对象在栈中。但这种方法的潜在劣势是搜索live对象的线性遍历,使标记的算法复杂度与代的大小相关,而不是与对象关系图中节点与点的数量相关。当搜索已标记对象的代价超过对已标记对象进行扫描的代价时,这时就会产生问题,而这只会发生在live对象很少的情况。
清理阶段
并发标记完成后,清理程序必须将那些没有被标记的对象记为可达的,并将其放到可用存储的池中。内存分配程序通常会划分出一个空闲块,在其中创建一个已分配内存块和并维护剩余的空闲块,这两个块都比原始的空闲块小。因此,为了防止块的平均大小越来越小,清理程序必须要做一些合并操作,即将一些连续的空闲块合并为一个大的空闲块。 在非并发的、基于空闲列表的垃圾回收中,清理和合并工作是很容易完成的,只需要将空闲块直接合并就行了。但是,在并发垃圾回收中,这种方法是不可行的,因为在清理过程中,仍有可能会分配内存。 并发内存分配是清理工作更加复杂,主要体现在2方面。一是,清理程序在处理空闲列表时,内存分配程序可能会在该空闲列表上分配内存。这种竞争可以通过使用互斥锁来解决。而是,清理线程可能会与mutator程序发生竞争。假设现在有3个连续块a、b、c,现在b在空闲列表中,a和c已经用于内存分配,但现在都已经是不可达的了。我们希望将a、b、c合并为一个大的空闲列表。但为了实现目的,我们首先要将b移出空闲列表中,否则b即可能被内存分配程序和清理程序同时使用。 这个问题可以使用互斥锁来解决,但在这个场景中,对空闲列表有一个额外要求,就是可以从列表中间执行移除操作。单项链表的实现在移除头部节点上很有效率,但若要移除中间节点就需要使用双向链表。
垃圾回收线程
使用专门的垃圾回收线程可以充分利用多CPU的优势。
与年轻代垃圾回收的交互
在分代式垃圾回收中,使用一些优化方法使并发垃圾回收器工作在老年代上。首先,我们发现,对于大部分程序来说,大部分在老年代上的内存分配可以通过从年轻代提升完成(其他由mutator直接在老年代分配的内存,通常是由于这些对象太大,以至于年轻代装不下)。在提升对象时,mutator线程和并发垃圾回收线程都会被挂起,这样更简便一些。充分利用这种简便性,可以实现在年轻代垃圾回收过程对“线性分配模式(linear allocation mode)”的支持。线性分配比基于空闲列表的分配快得多(尤其是与双向链表实现相比),因为只需要更少的指针比较和修改。线性分配模式可以极大的加快提升对象的速度,而提升对象又是年轻代垃圾回收导致的性能损耗的主要部分。 在Resaerch VM的默认配置中,会对老年代进行压缩,来简化年轻代的工作。在分代式系统中,from区的一部分对象会被拷贝到to区,还有一部分会被提升到老年代,而这些对象也是待扫描对象集合的一部分。老年代进行压缩时,因此是线性分配的,这些被提升待扫描的对象是连续存放的。但是在非压缩的垃圾回收中,被提升的对象可能不是连续存放的。这样会使定位对象的工作变得复杂,它们有可能会被扫描到。 对这个问题的解决方法是使用一个链表来记录那些被提升但没有被扫描的对象。每个被提升的对象都是从from区提升的,而且该对象的from版本中包含了一个前向指针,指向该对象在老年代的新地址。被提升的对象作为链表的节点,前向指针指向元素集合,使用一个子序列头字作为链表的next域。
并发
理想情况是,大部分老年代内存分配的工作可以在年轻代垃圾回收的过程中完成,因此,在执行年轻代垃圾回收时,将老年代垃圾回收的工作挂起可以解决部分问题。但无法解决所有问题,mutator仍有可能在直接在老年代分配内存,而老年代垃圾回收线程一定不可以在关键区域(critical section)被年轻代垃圾回收中断,否则会造成数据不一致。 老年代的内存分配可以是直接分配的,也可以是从年轻代提升上来的,这里会有两个问题。一是,如果后台的垃圾回收先正处在清理阶段,那么必须要保证对空闲链表和标记位的访问的一致性。如果空闲块b是在清理阶段分配的内存,那么必须要保证清理线程不会将其标识为已分配但未标记的对象。因此,在标记阶段,会使用allocate-live策略:已被配的内存块在位图中被标记为live。这种标记必须与清理线程中对标记位的检查合拍。 处于某种原因,在标记过程中也可能会分配内存。如果一个对象是在标记过程中分配的内存,并且在标记结束后,该对象 也是可达的,那么必然存在一条从根到该对象的路径,这样最终标记也可以获得一个正确的传递闭包。每个这样的路径要么包含 所有在标记过程中分配的未标记对象,或者至少包含一个已标记对象。重点是后一种情况,这里考虑路径中最后一个被标记的对 象,在被扫描之后(因此才是已标记的)必然被修改了,才能成为路径的一部分,或者是路径上的下一个对象将要被标记。因此, 使该对象成为路径中一部分的那次修改将该对象标记为“脏(dirty)”。所以,路径上最后一个被标记的对象必定是脏的,即标记为live、dirty的对象可以指向在标记阶段被分配内存的对象。 上述的方法可以准确的处理一些并发问题,但这也是有代价的。如果在标记阶段要给大量对象分配内存,而且其中很多对象在最终标记之前都是可达但未标记的,那么这些对象只能等到最终标记时处理,会增大程序暂停时间。
并发预清理
如果一个应用程序中,对对象的更新操作非常频繁,就会产生很多“脏对象”,它们在最终标记中会被中心扫描,大大增加程序暂停时间。这个问题可以使用并发预清理来解决(concurrent preclean)。 只要小心谨慎的执行操作,那么在最终标记中对“脏对象” 的大部分操作都可以在最终标记之前并发完成。在并发标记结束后,无需挂起mutator,找出所有的“脏对象”,对于每个脏对象,都标记为clean,并从该对象开始进行传递标记。由于之后的mutator所执行的更新操作还会弄“脏”相关对象,并在最终标记之前处理该对象,所以正确性在总体上仍得以保持。希望的结果是,并发预清理程序可以用比并发标记少得多的时间完成预清理工作,这样mutator就是有很少的时间来弄脏对象。因此,最终标记阶段就可以少做一些工作,降低应用程序暂停时间。 在另外一些实验中,有两种方式对并发预清理进行扩展。首先,预清理的原始实现进行仅仅在mod union table上工作,并假设在两次年轻代垃圾回收之间,反映在卡表的修改数量较小。但实际情况有时并不是这样,因此,对并发预清理的扩展就是加入对卡表的清理工作。这需要创建一个新的卡表值,“脏表”,表示由于分代垃圾回收而弄脏的卡片,分代式垃圾回收认为这些卡片是dirty的,而在最终标记中,认为他们是clean。其次,需要对脏卡片进行迭代处理,直到脏卡片的数量下降到一定比例(当前是1/3),或者下降到一定数量(当前是10000)。